Scientists propose an imitation learning algorithm, effectively aligning the int
Embodied intelligent agents with multimodal capabilities are the most important components for achieving general artificial intelligence. People hope that they can be implemented to assist in completing everyday tasks, such as common household chores, autonomous driving, and robot operations.
Currently, there is no widely recognized technical solution in the field that can effectively train multimodal embodied intelligent agents.
In large language models, there is a well-known theory called Scaling Laws. Simply put, the larger the model and the more data it has, the better the performance will be. However, it is difficult to replicate the success of large language models in training embodied intelligent agent tasks.
The main reasons are:
First, unlike the vast amount of textual data used to train large language models, data related to embodied intelligence is very singular and expensive (at the level of tens of millions of yuan); second, there is a lack of effective training methods like supervised learning.Based on this, the Southern University of Science and Technology, in collaboration with the University of Maryland, College Park, the University of Technology Sydney in Australia, and the JD Exploration Academy, among other teams, has proposed a new embodied intelligent agent training framework to address the misalignment between the training of multimodal embodied agents and environmental changes.
Advertisement
By leveraging large language models to provide experiential feedback and guidance in imitation learning for the agent, the success rate of household robot task completion has been significantly improved.
In previous studies, it was commonly believed that as long as the offline dataset was large enough, the performance of the embodied intelligent agent would be better.
This research offers a new perspective for the field: even if the dataset is large enough, the changes in the future world are infinite and it is difficult to enumerate and generalize all possibilities. Therefore, it is necessary to collect feedback data from the environment in real-time and continue to learn through interaction.
Recently, the related paper, titled "Embodied Multi-Modal Agent trained by an LLM from a Parallel TextWorld," was published on the preprint website arXiv[1] and has been accepted by the CVPR 2024 conference.The article is translated into English as follows:
Yan Yijun, a Ph.D. student at Southern University of Science and Technology (SUSTech), is the first author. Professor Shi Yuhui, a chair professor at SUSTech, and Dr. Shen Li from JD Exploration Academy (currently an associate professor at Sun Yat-sen University), serve as the co-corresponding authors.
Key Issue: Dynamic Misalignment Between Agents and Environments
Researchers aim to train embodied agents to follow language instructions from visual input states. However, under the current framework, such embodied agents are often trained and learned from offline, static datasets, which can lead to a series of issues such as hallucinations, distribution shifts, and sparse rewards.
Specifically: (The text is cut off here, so the specific issues are not listed.)First, hallucinations, also known as misalignment with human goals.
An agent trained on a fixed, offline dataset can only reflect events that occurred in the world up to a certain point in time.
However, the world is dynamically changing. If the agent encounters a scene or situation that has never appeared in the dataset before, it will perform operations or actions that seem unreasonable to humans, which is commonly referred to as the "hallucination phenomenon." This is specifically manifested as the agent performing incorrect, unreasonable, and dangerous behaviors.
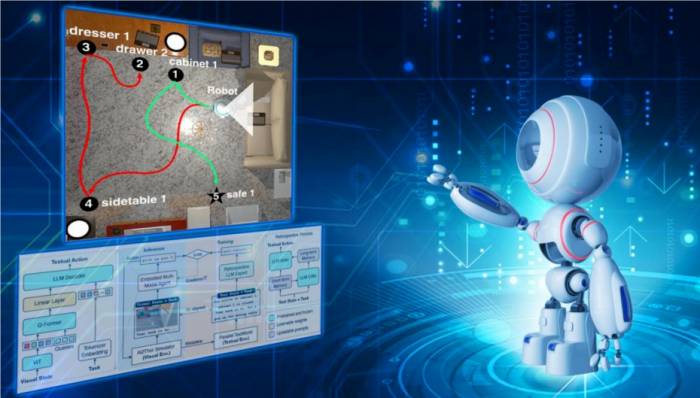
Yang Yijun pointed out, "To completely solve the problem of hallucinations in agents, the most direct method is to let the agent continuously interact with the environment, collect feedback data from the environment in real time, and continue to interact and learn, and keep this cycle going."
Second, distribution shift, also known as misalignment with environmental dynamics.The distribution shift problem is akin to an illusion, referring to the discrepancy between the data distribution originally learned and the distribution of future data. Over time, as decisions are made, the data distribution is also continuously changing, thus creating a shift that can lead to anomalies in the actions or model outputs of an intelligent agent that has been fully trained on the original dataset.
Thirdly, there is the issue of sparse rewards. In fact, by using a method similar to reinforcement learning, where an intelligent agent is trained through interaction with the environment, the feedback obtained from the environment can be very sparse.
Yang Yijun explained, "The successful completion of a task requires the accumulation of multiple decision steps. However, the intelligent agent may not receive any valuable feedback at some intermediate steps or at all steps, only receiving the feedback of success after the final task is completed."
Therefore, if the intermediate steps of the task are too long and the intelligent agent is not guided step by step through feedback, it may find it difficult to achieve the final goal.Training Embodied Agents with Large Language Models through Cross-Modal Training
In this study, Assistant Professor Tianyi Zhou from the University of Maryland, College Park, summarized the key issue of the dynamic misalignment between the agent and the environment mentioned above.
After team discussions, Yang Yijun proposed that by continuously interacting with the environment and then using a large language model to provide step-by-step guidance based on environmental feedback, the strategy of the agent can be trained more efficiently.
"In fact, we are one of the earlier teams in the field to be aware of the dynamic misalignment problem between the agent and the environment, which was also affirmed by the reviewers at the CVPR 2024 conference," he said.
Researchers proposed a cross-modal imitation learning algorithm framework to obtain real-time feedback about the environment. It should be understood that in imitation learning, there are two key roles: Teacher/Expert and Student/Embodied Agent.After obtaining the state information of the environment, it is first input to the large language model "teacher", and then the "teacher" summarizes and feeds back to output a more easily learnable target for the "student" to imitate.
Yang Yijun said: "The teacher's output solves the previously existing problem of sparse rewards. In this way, for each step of environmental feedback, the teacher can provide guidance to the student, solving the problem of only knowing whether it is successful after all tasks are completed."
In terms of imitation learning, the traditional method is to use human annotations for training and guiding learning. For example, provide several options at each step, and then let people choose the option that is most helpful for completing the final goal in execution.
It should be understood that learning from human feedback is not only time-consuming and labor-intensive, but also requires the person providing feedback to have professional subject knowledge, especially for issues related to robots, which will increase the cost of annotation.
At present, large language models have been able to complete many types of tasks, including some decision-making tasks. Therefore, this research group innovatively proposes to use large language models to replace humans to provide feedback signals in the process of imitation learning.They invoked the GPT-4 model, allowing it to choose among the available actions at each step, as the environmental feedback selects more appropriate text actions, and further guides the "student" to achieve the ultimate goal.
The success rate is about 91% when people perform labeling operations according to the scene. Without human intervention and only under the condition of the scene seen by the robot's camera, the success rate is about 20%.
The team, based on the simulated environment ALFWorld rendered by Unity3D, which includes thousands of different household labor scenarios, requires the robot to complete command tasks such as washing dishes, picking up apples, and taking out the trash. The success rate of tasks has significantly increased by 20%-70% through this new method of training the intelligent agent, ultimately achieving a success rate of 88%.
"This is also the only method that is close to the human success rate at present. In the future, if our method further achieves scale effects, there is hope to use larger models to reach or exceed a 91% success rate in the test environment," said Yang Yijun.
Will continue to expand the embodied intelligent agent training framework.Before the emergence of large language models, Yang Yijun's research direction was reinforcement learning, including offline reinforcement learning, continuous reinforcement learning, and so on. These explorations have laid a solid foundation for this research and have a certain enlightening and promoting effect.
"Based on the consideration of applying technology to practical problems, with the advent of large language models, my research direction has gradually shifted to using the prior knowledge of large language models to help improve the efficiency of reinforcement learning algorithms," he said.
It is undeniable that the biggest problem with reinforcement learning is that it requires a huge amount of data to learn a relatively ideal strategy through continuous interaction and trial and error with the environment. However, the data in embodied intelligence is expensive, which is also one of the most difficult problems to solve.
Next, the research group plans to continue to expand this method to achieve higher performance. Yang Yijun said, "We will try to introduce human feedback into the algorithm framework. Moreover, human feedback can be mixed with the feedback of large language models to solve the problem of high cost."
On the other hand, they also plan to try to solve the problem of too many interactions between data and the environment from the perspective of optimizing imitation learning algorithms. In fact, the number of interactions between the agent and the environment is closely related to the cost. Researchers hope to limit the number of interactions with the environment as much as possible while achieving the same learning performance.For example, by using meta-learning, robots can reuse prior knowledge that is common-sense and general, which they have been trained on before, to help speed up the completion of similar tasks (continuous reinforcement learning). To a large extent, this method can reduce the deployment of interaction with the environment.
Yang Yijun gave an example, saying: "For instance, if a robot has already learned to wash dishes, when it is asked to learn to wash bowls, it is essentially similar to washing dishes."
In the past, many people believed that only algorithms designed with enough ingenuity could truly solve a problem. However, with the emergence and development of large language models, the way people view solving artificial intelligence problems has gradually changed.
The current situation is that algorithms can be simple enough, but the required computational resources and data volume need to be large enough. That is to say, compared with algorithms, data and computing power resources have become more important.
Previously, artificial intelligence research mainly focused on perceptual problems, which solved the problem of being able to recognize objects or functions, such as using computer vision for detection and segmentation, depth estimation, object recognition, etc.When discussing the potential next steps in the development of artificial intelligence, Yang Yijun stated: "The next step for artificial intelligence should be the transition from perceptual issues to decision-making issues."
In the future, it is hoped that the approach to solving problems with the aid of large language models, with more data, greater computing power, and larger models, will be used to address decision-making issues.
"On decision-making issues, we look forward to the emergence of a universal decision-making model to solve a variety of decision-making problems. I believe this could be a milestone development for the future," Yang Yijun concluded.
Leave a Reply